 Comprar cripto
Comprar cripto- Mercados
 Futuros
Futuros- Spot
- Copy Trade
- Renda
- Mais
A Jornada de Claude para a Tolosidade em Diagramas: O Custo da Economia, ou Como a Fatura da API Aumentou 100 Vezes
Há alguns dias, Stella Laurenzo, Chefe de IA na AMD, postou um problema intitulado "Código Claude Inutilizável para Tarefas de Engenharia Complexas" no repositório oficial do Código Claude. Isso não foi uma reclamação emocional de um usuário, mas uma análise quantitativa baseada em 6.800 sessões. Isso trouxe à tona a questão que a comunidade de IA mais reluta em enfrentar, com um conjunto de números se destacando particularmente: uma configuração de economia de custos ajustada pela Anthropic fez a fatura mensal da API desta equipe disparar de $345 para $42.121.
A equipe de Laurenzo rastreou 235.000 invocações de ferramentas, 18.000 prompts e documentou a degradação sistemática do desempenho do Código Claude desde fevereiro de 2026. Este relatório foi posteriormente coberto pelo The Register, provocando uma tempestade de opinião pública na comunidade de desenvolvedores que durou duas semanas.
Boris Cherny, Chefe da equipe do Código Claude da Anthropic, forneceu uma explicação no Hacker News. Em 9 de fevereiro, com o lançamento do Opus 4.6, um mecanismo de "auto-pensamento" foi ativado por padrão, onde o modelo decide autonomamente a duração do pensamento. Em 3 de março, a Anthropic então reduziu o esforço de pensamento padrão para 85. A explicação oficial foi "o ponto de equilíbrio ideal entre inteligência, latência e custo." O impacto real desses dois ajustes é evidente nos dados.
A Profundidade do Pensamento Cai em Três Quarters
De acordo com os dados da Issue do GitHub de Stella Laurenzo, a profundidade média do pensamento do Código Claude passou por um colapso em três estágios ao longo de dois meses: de um máximo de 2.200 caracteres no final de janeiro para 720 caracteres até o final de fevereiro, uma queda de 67%. Em março, ela encolheu ainda mais para 560 caracteres, uma diminuição de 75% em relação ao pico.
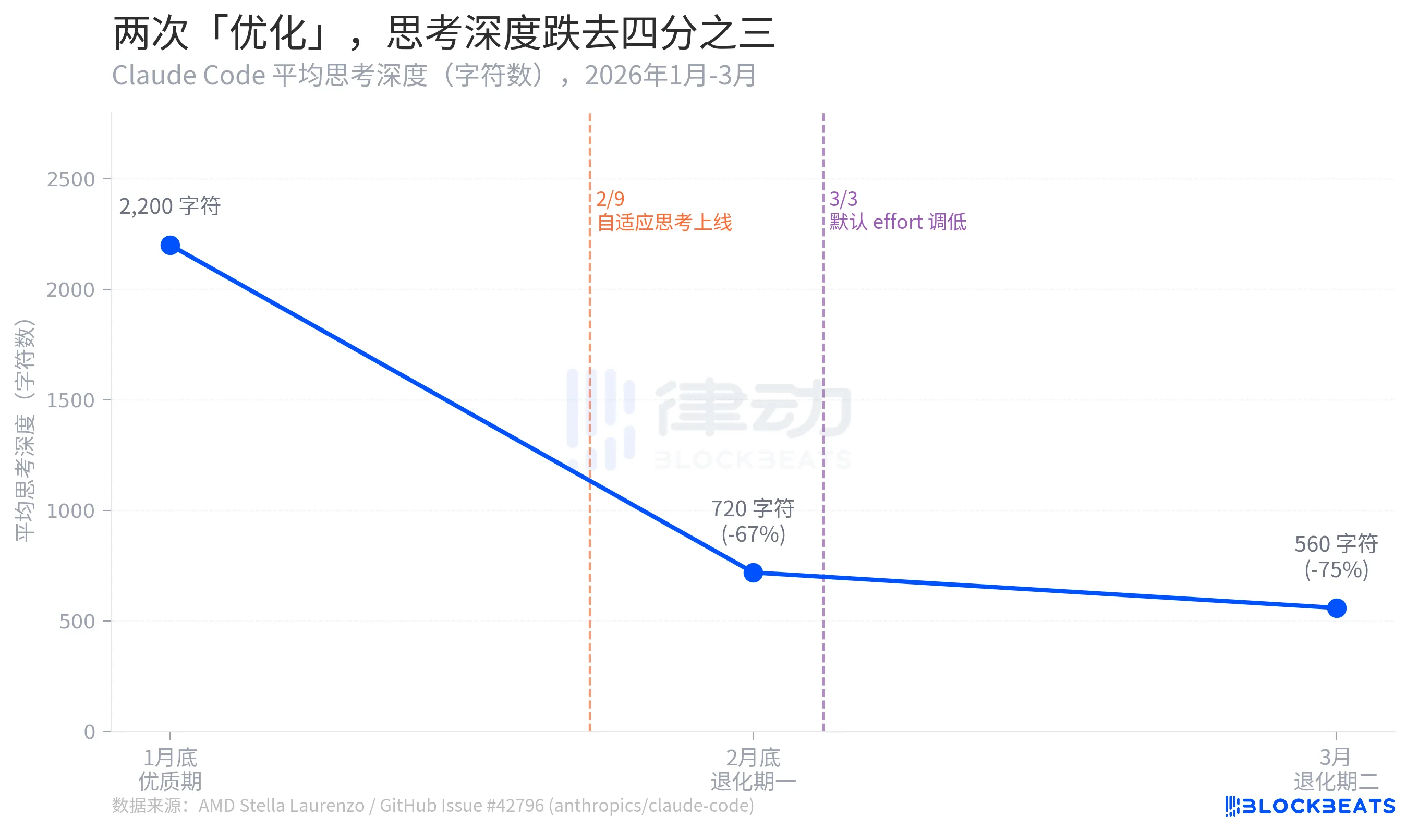
A profundidade do pensamento aqui é uma métrica proxy que reflete quanto "deliberação interna" o modelo está disposto a engajar antes de fornecer uma resposta. A diferença entre 2.200 e 560 caracteres é aproximadamente equivalente a degradar de "redigir antes de responder" para "pensar por dois segundos na sua cabeça antes de falar."
Laurenzo também apontou que o recurso de "Redação de Conteúdo do Pensamento" (redact-thinking-2026-02-12) lançado no início de março coincidiu com a ocultação do processo de pensamento do modelo durante este período, tornando a diminuição menos perceptível para os usuários. Boris Cherny insiste que isso foi meramente uma mudança na interface e did-133">não afetou o raciocínio subjacente. Ambas as alegações são tecnicamente válidas, mas, do ponto de vista do usuário, o efeito é indistinguível.
Boris Cherny mais tarde reconheceu que, mesmo configurando manualmente o esforço de volta ao máximo, o mecanismo de auto-reflexão ainda pode alocar raciocínio insuficiente em algumas rodadas, levando a conteúdos alucinatórios. "Restaurar o esforço máximo" não é uma solução completa; isso apenas ajusta o botão de volta para mais perto de sua posição original, em vez de restaurá-lo ao seu determinismo original.
De "Programador Orientado a Pesquisa" para "Programador de Edição Cega"
Um detalhe no relatório de Stella Laurenzo é mais explícito do que a profundidade de pensamento: quantos arquivos relevantes o modelo lê ativamente antes de fazer alterações no código.
De acordo com os dados da Issue do GitHub, durante o período principal, a média da razão de leitura para edição é de 6,6. Antes de fazer uma alteração no código, o modelo, em média, lê 6,6 arquivos para entender o contexto. Durante o período de decadência, esse número cai para 2,0, uma diminuição de 70%. Mais criticamente, cerca de um terço das edições de código ocorrem sem que o modelo leia o arquivo alvo, mergulhando diretamente.
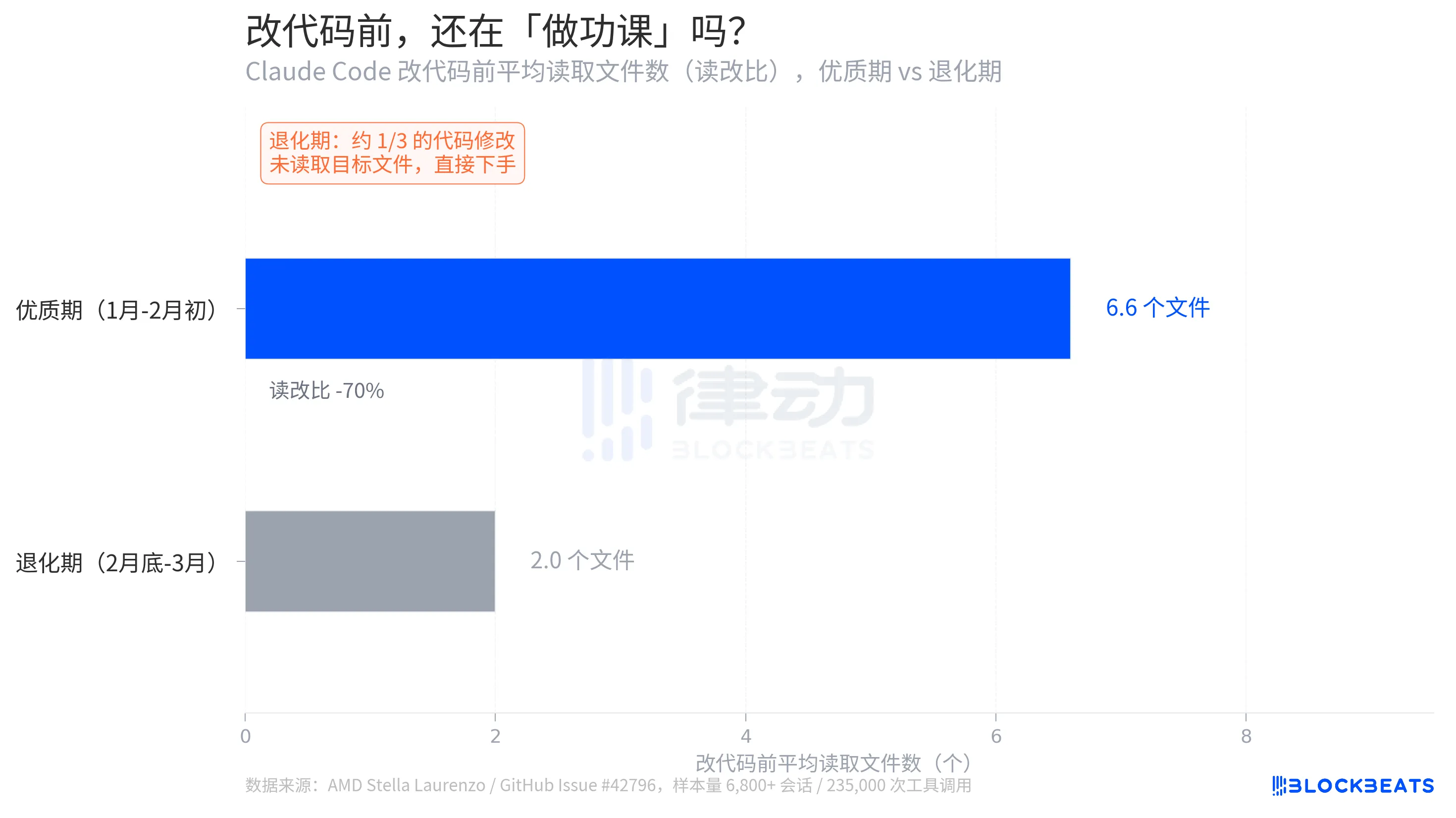
Laurenzo se refere a isso como "edições cegas." Em termos de engenharia, isso é semelhante a um programador escrevendo código sem olhar para as assinaturas das funções ou conhecer os tipos de variáveis. "Todo engenheiro sênior da minha equipe teve experiências semelhantes em primeira mão," ela escreveu em seu relatório. "Claude não pode mais ser confiável para realizar tarefas de engenharia complexas."
A queda de uma razão de leitura para edição de 6,6 para 2,0 não é apenas uma mudança de métrica comportamental; isso significa um colapso nas taxas de sucesso de tarefas. A complexidade dos repositórios de código modernos dita que qualquer modificação envolve dependências em vários arquivos. Pular a exploração do contexto e fazer alterações diretamente não leva apenas a "respostas incorretas", mas sim a "mudanças aparentemente corretas que desencadeiam novos erros a montante." O custo de depurar tais erros supera em muito o de uma única resposta explícita falha.
O Paradoxo de "Economizar Dinheiro"
Um dos conjuntos de números mais contra-intuitivos em todo o incidente vem dos mesmos dados da Issue do GitHub: A equipe de Stella Laurenzo viu os custos mensais de invocação da API Claude Code despencarem de $345 em fevereiro de 2026 para impressionantes $42.121 em março, um aumento de 122 vezes.
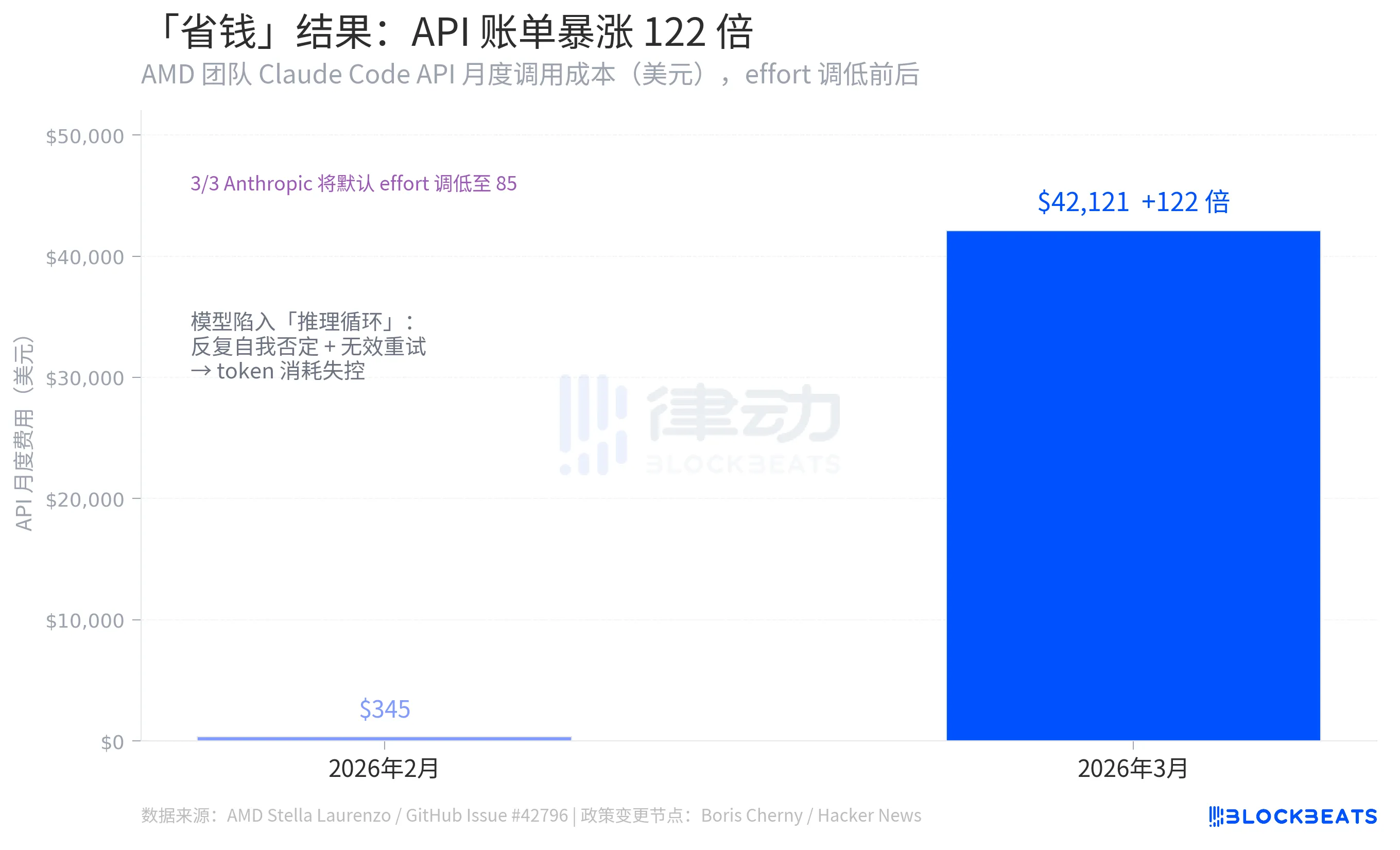
A lógica por trás da redução de esforço da Anthropics era diminuir o consumo de tokens por chamada, reduzindo assim os custos. No entanto, o resultado foi o oposto. A razão para isso foi o surgimento de numerosos "ciclos de raciocínio" após a degradação do modelo, levando a uma auto-negativa repetida dentro de uma única resposta, reinícios constantes e um consumo de tokens muito superior ao montante economizado. De acordo com os dados de Stella Laurenzo, a taxa de usuários que abortavam tarefas voluntariamente aumentou em 12 vezes durante o mesmo período, exigindo intervenção contínua, correção e reenvio por parte dos desenvolvedores.
A lógica subjacente é um erro sistêmico. Reduzir a potência computacional em uma tarefa complexa não simplesmente reduz proporcionalmente os custos. Uma vez abaixo de um certo limite de raciocínio, o modelo começa a se desviar do caminho, e o custo total acaba aumentando. Reduzir o esforço economizou dinheiro em consultas simples, mas em tarefas de codificação, aumentou a conta.
A questão do "Empobrecimento", o GPT-4 fez isso há três anos.
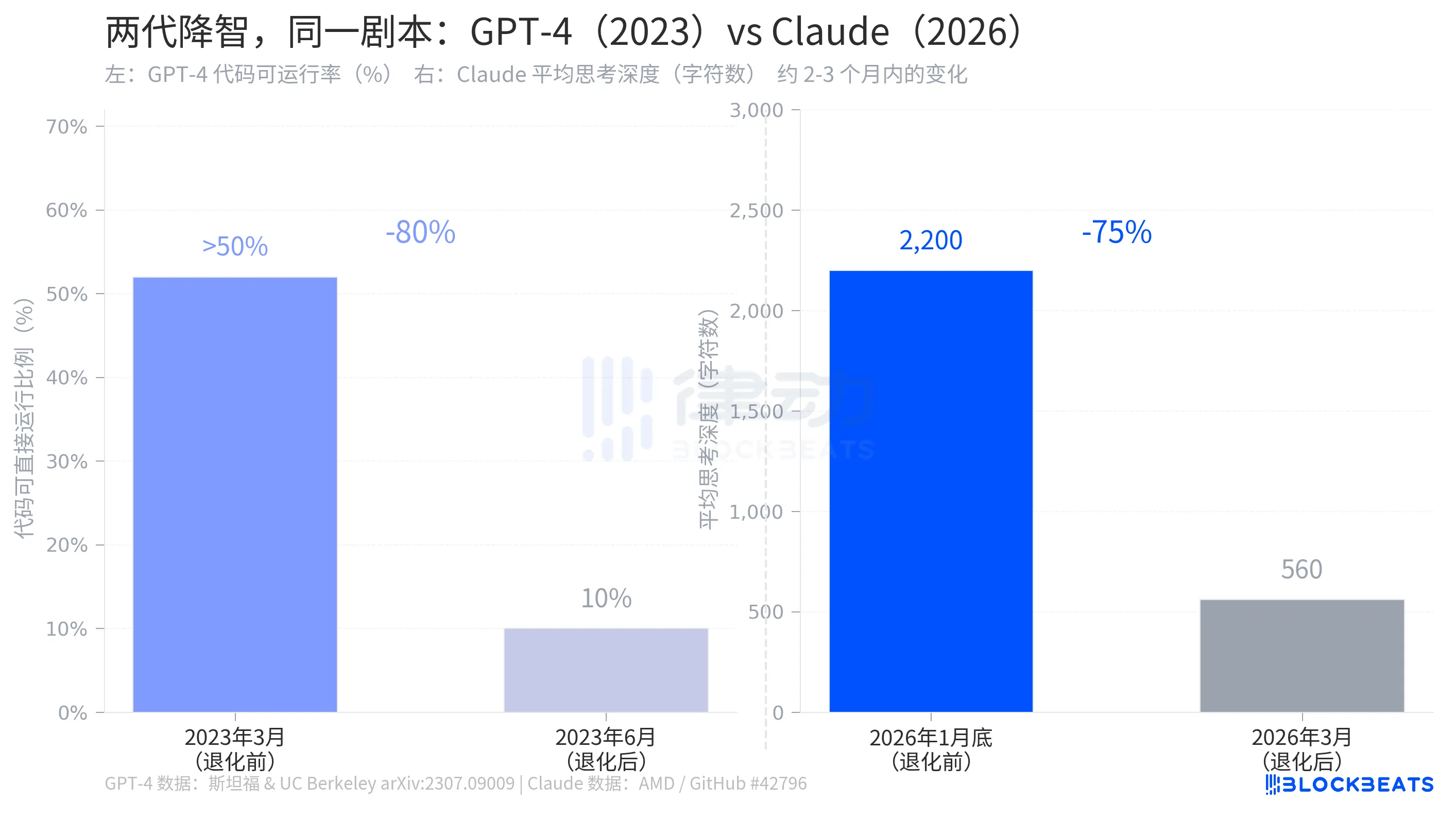
Em julho de 2023, uma equipe de pesquisa da Universidade de Stanford e da Universidade da Califórnia, Berkeley, publicou um artigo no arXiv intitulado "Como o comportamento do ChatGPT está mudando ao longo do tempo?", documentando o mesmo fenômeno que ocorreu no GPT-4.
De acordo com os dados da pesquisa, em março de 2023, o GPT-4 havia gerado código onde mais de 50% era diretamente executável. Em junho, essa proporção caiu para 10%, uma diminuição de 80% em três meses. Durante o mesmo período, a precisão na identificação de números primos despencou de 97,6% para 2,4%. A resposta da OpenAI foi muito semelhante à da Anthropic: houve otimizações em segundo plano, parte da iteração normal.
A estrutura das duas histórias é quase idêntica: uma empresa de IA ajustou silenciosamente parâmetros que afetam as capacidades do modelo em segundo plano, os usuários notaram, a empresa reconheceu o ajuste, mas explicou como "uma alocação de recursos mais razoável." A degradação do GPT-4 ocorreu em 2023, a degradação do Claude aconteceu em 2026, três anos de diferença, mas o roteiro é o mesmo.
Isso não é um erro peculiar de uma empresa específica. A lógica econômica dos modelos de assinatura de IA determina que, quando os custos de raciocínio excedem o preço que pode ser coberto, os fabricantes enfrentam a mesma pressão. Reduzir a intensidade de pensamento padrão é atualmente o ajuste mais fácil a ser feito entre custo e desempenho. O que os usuários percebem é que o modelo está "ficando mais burro." O que o fabricante economiza nos livros é o custo marginal por chamada.
Boris Cherny forneceu uma solução técnica onde os usuários podem restaurar manualmente a intensidade do pensamento para o nível mais alto através do comando /esforço alto ou modificando o arquivo de configuração. Essa solução é tecnicamente viável, mas também significa que "máximo desempenho" não é mais a configuração padrão.
De $345 a $42.121, o que foi gasto não foi apenas o orçamento, mas também uma suposição: as mudanças na configuração padrão feitas pelo fabricante tinham a intenção de melhorar a experiência do usuário.
Você também pode gostar

1 bilhão de DOTs foram criados do nada, mas o hacker só conseguiu 230.000 dólares

Declarar guerra à IA? A narrativa do Juízo Final por trás da Residência em Chamas do Ultraman

Os VCs de criptomoedas estão mortos? O ciclo de extinção do mercado começou

Regressão da Terra de Borda: Uma revisão sobre o poder marítimo, a energia e o dólar
Última entrevista com Arthur Hayes: Como os investidores de varejo devem lidar com o conflito no Irã?

Há pouco, Sam Altman foi atacado novamente, desta vez a tiros

Straits Blockade, Stablecoin Recap | Rewire Notícias Edição da manhã

Governador da Califórnia Assina Ordem para Banir Insider Trading em Mercados de Previsão
O Governador da Califórnia, Gavin Newsom, assinou uma ordem executiva para coibir o uso de informações privilegiadas em…

De altas expectativas a reviravolta controversa, o Airdrop da Genius desencadeia reação negativa da comunidade

A fábrica de veículos elétricos da Xiaomi no distrito de Daxing, em Pequim, tornou-se a nova Jerusalém para a elite americana

Equipamento leve, habilidade avançada: A verdadeira fonte de um aumento de 100 vezes na produtividade com IA

Ultraman não tem medo de sua mansão ser atacada; ele tem uma fortaleza.
Negociações entre EUA e Irã fracassam; Bitcoin enfrenta batalha para defender a marca de US$ 70.000
Reflexões e Confusões de um Crypto VC

Notícias da Manhã | Ether Machine cancela acordo de SPAC no valor de US$ 1,6 bilhão; SpaceX detém aproximadamente US$ 603 milhões em Bitcoin; Michael Saylor divulga novamente informações sobre o Bitcoin Tracker
Previsão das notícias desta semana | Os EUA divulgarão os dados do IPP de março; o presidente francês Macron fará um discurso na Paris Blockchain Week

Crypto ETF Semanal | Na semana passada, o influxo líquido para ETFs de Bitcoin à vista nos EUA foi de 816 milhões de dólares; o influxo líquido para ETFs de Ethereum à vista nos EUA foi de 187 milhões de dólares