

圖解Claude越用越笨:省錢的代價,是API帳單漲了100倍
幾天前,AMD AI 團隊負責人 Stella Laurenzo 在 Claude Code 官方存儲庫發布了一份標題為「Claude Code 對複雜工程任務已無法使用」的問題報告。這不是一條用戶情緒化的投訴,而是一份基於 6,800 個會話的定量分析。它把 AI 圈最不願面對的問題擺上了桌面,其中有一組數字尤其刺眼:Anthropic 為省算力做的配置調整,把這個團隊的 API 月度帳單從 345 美元燒到了 42,121 美元。
Laurenzo 的團隊追踪了 235,000 次工具調用、18,000 條提示詞,記錄了 Claude Code 從 2026 年 2 月起出現的系統性能力退化。這份報告隨後被 The Register 報導,在開發者社區引發了持續兩周的輿論風暴。
Anthropic Claude Code 團隊負責人 Boris Cherny 在 Hacker News 作出了說明。2 月 9 日隨 Opus 4.6 發布時,默認啟用了由模型自主決定思考時長的「自適應思考」機制。3 月 3 日,Anthropic 又把默認思考強度(effort)調低至 85。官方的解釋是「在智能、延遲與成本之間的最佳平衡點」。這兩次調整的實際效果,數據說得很清楚。
思考深度,跌了四分之三
據 Stella Laurenzo 的 GitHub Issue 數據,Claude Code 的平均思考深度在兩個月內經歷了三段式崩塌:1 月底優質期的 2,200 字元,到 2 月底跌至 720 字元,跌幅 67%。3 月進一步萎縮至 560 字元,較峰值跌去 75%。
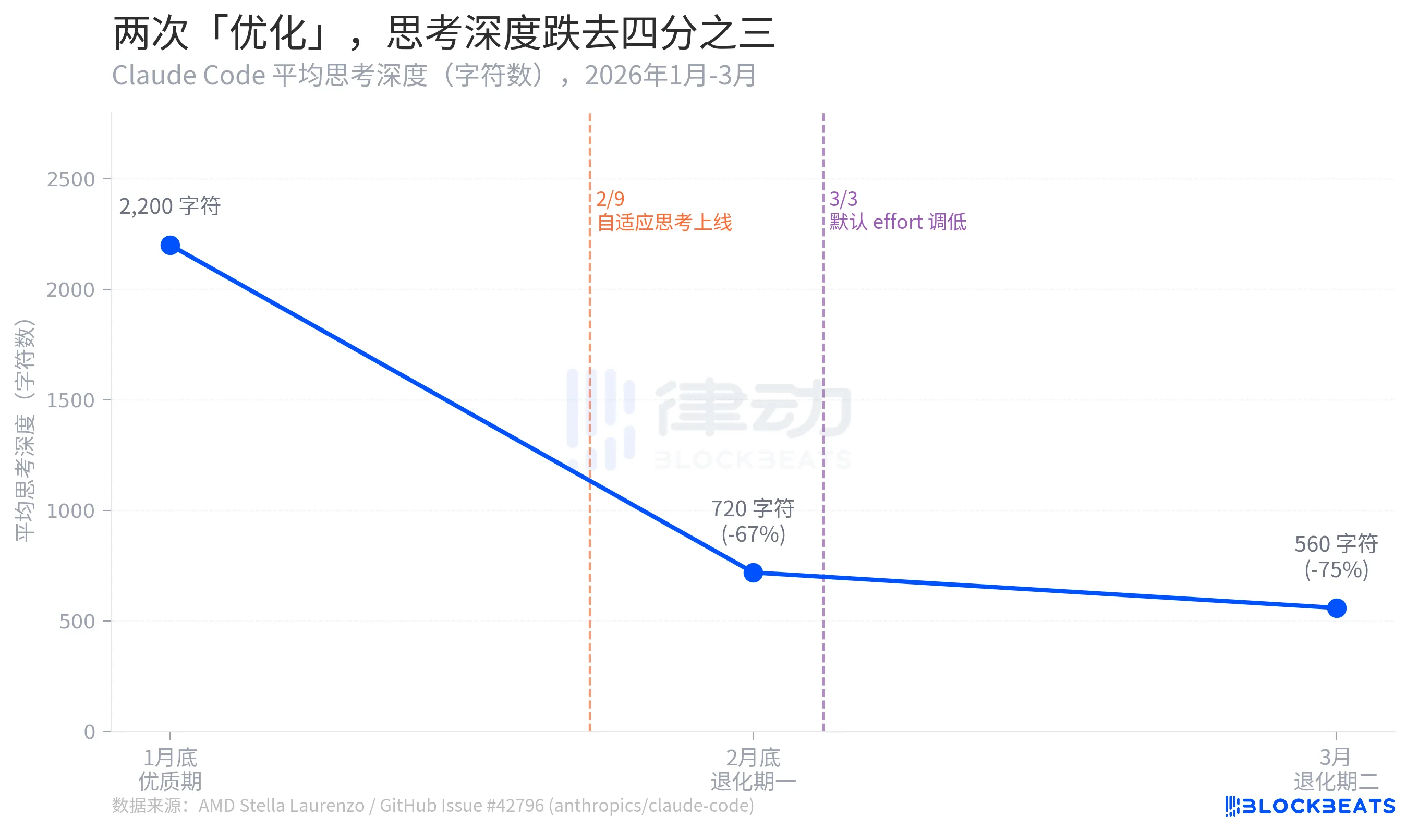
思考深度在這裡是個代理指標,反映模型在給出答案前願意投入多少「內部推演」。2,200 字元和 560 字元的差距,大致等同於從「寫完草稿再作答」退化為「腦子裡想兩秒就開口」。
Laurenzo 還指出,3 月初上線的「思考內容隱藏」功能(redact-thinking-2026-02-12)恰好在這段時間遮蔽了模型思考過程,讓用戶無法直觀感知縮水。Boris Cherny 堅持這只是界面改動,不影響底層推理。兩種說法在技術上都成立,但從用戶側來看,效果上沒有區別。
Boris Cherny 後來也承認,即使手動將 effort 設回最高,自適應思考機制仍可能在某些輪次分配推理不足,並可能產生幻覺內容。「恢復最高 effort」並不是一個完整的解法,它只是把旋鈕拨回了靠近原來的位置,而不是恢復到原有的確定性。
從「研究型程式設計師」到「盲改型程式設計師」
Stella Laurenzo 的報告裡有個細節比思考深度更直白:改代碼前,模型會主動讀多少個相關檔案。
據 GitHub Issue 數據,優質期的平均讀改比是 6.6,改動一處代碼前,模型平均會先讀 6.6 個檔案,了解上下文。退化期這個數字跌到 2.0,降幅 70%。更嚴重的是,約三分之一的代碼修改發生在模型未讀取目標檔案的情況下,直接下手。
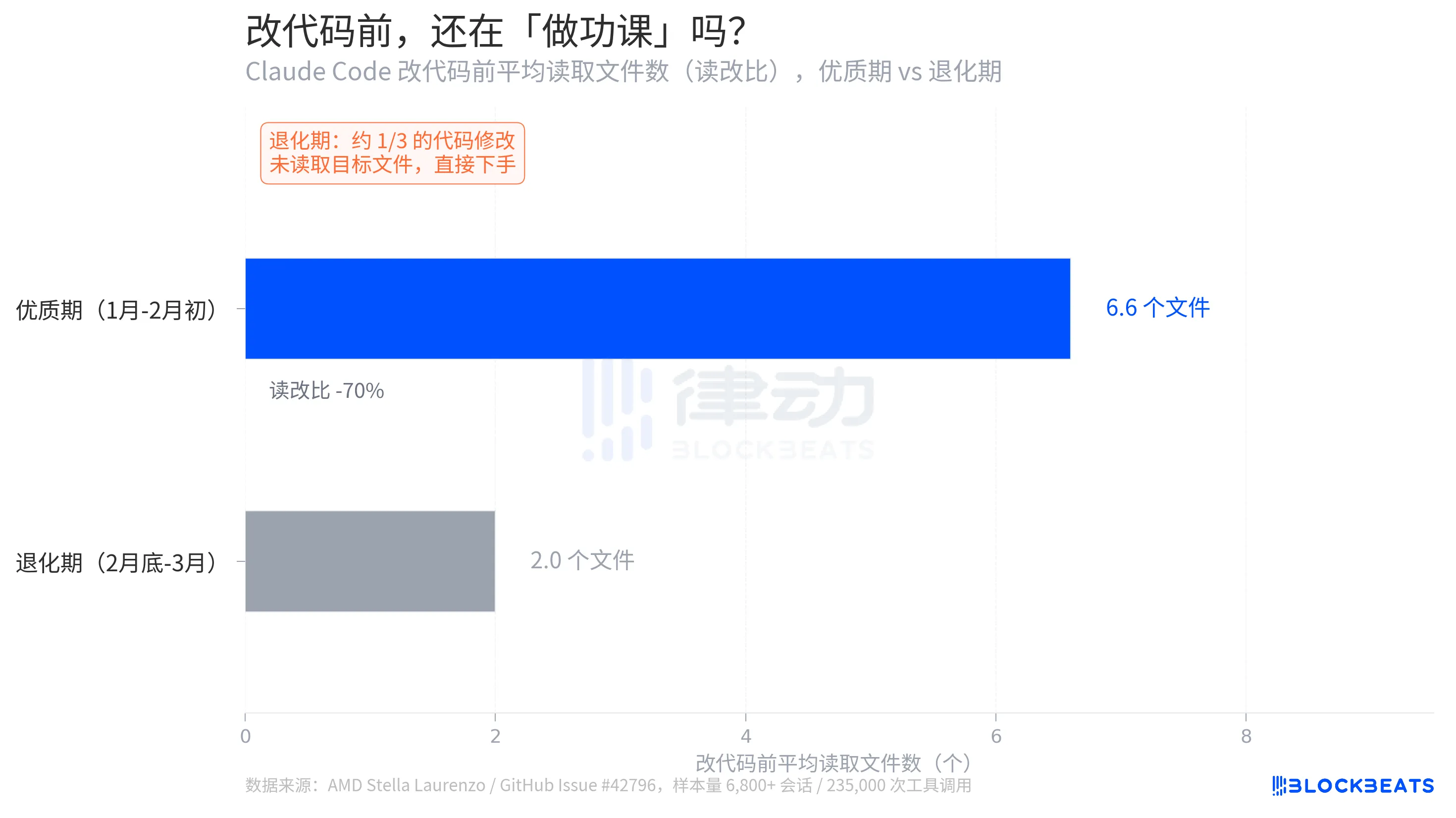
Laurenzo 講之為「盲改」(blind edits)。工程上,這相當於一個程式設計師在不看函數簽名、不知道變數類型的情況下就開始寫代碼。「我團隊的每一位高級工程師都有類似的親身遭遇。」她在報告中寫道,「Claude 現在不能被信賴去執行複雜的工程任務。」
讀改比從 6.6 到 2.0,表面是一個行為指標的變化,底層是任務成功率的塌陷。現代代碼庫的複雜度決定了,任何修改都牽涉多個檔案之間的依賴關係。跳過上下文探索直接修改,產生的錯誤不是「答錯了」,而是「看起來對,但會在下游觸發新的錯誤。這類錯誤的排查成本,遠高於一次失敗的明確回答。
「省錢」這件事,算反了
這是整個事件裡最反直覺的一組數字,來自同一份 GitHub Issue 數據:Stella Laurenzo 團隊的 Claude Code API 月度調用成本,從 2026 年 2 月的 345 美元,到 3 月飆升至 42,121 美元,漲幅 122 倍。
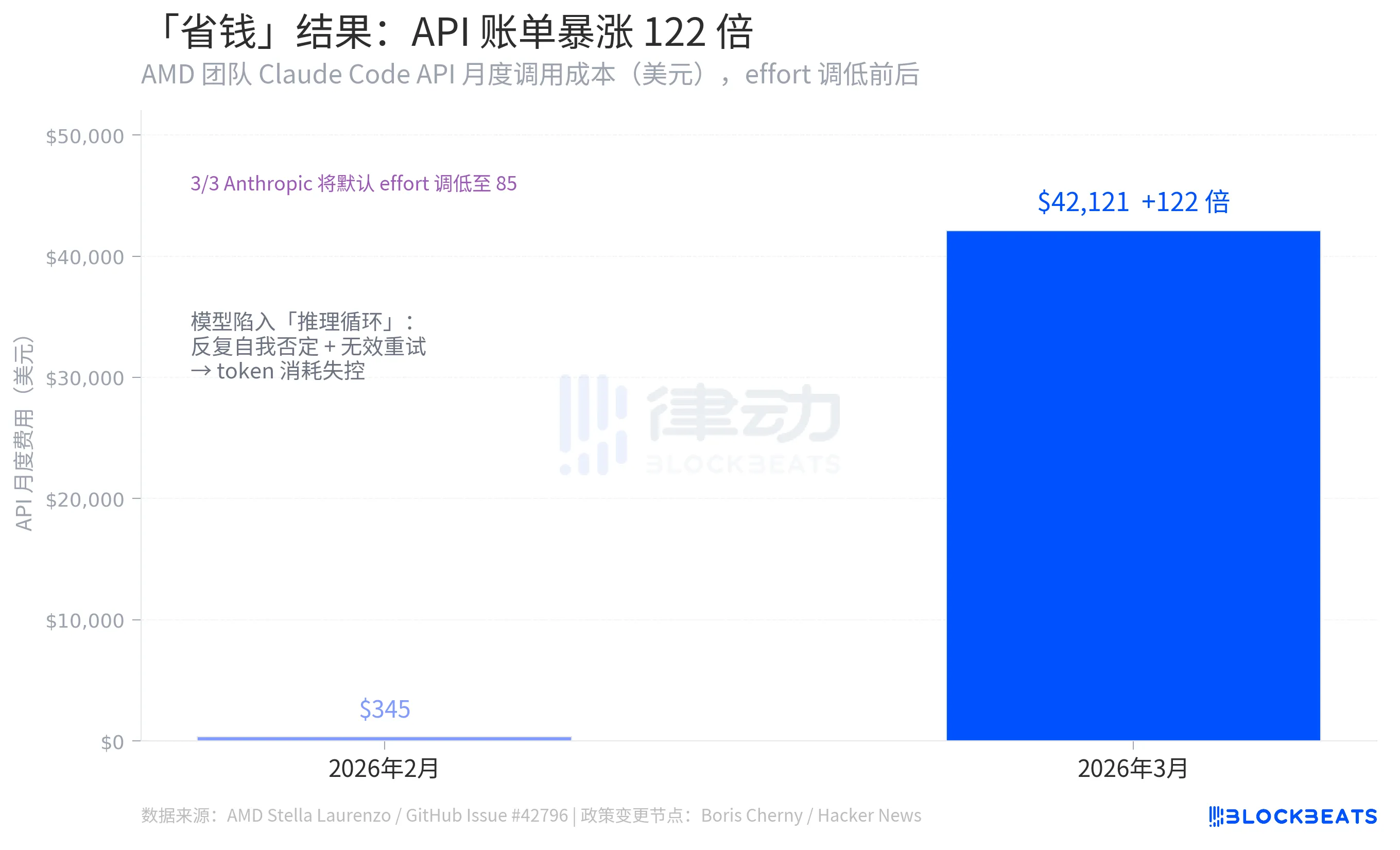
Anthropic 調低 effort 的邏輯是減少單次調用的 token 消耗,從而降低成本。但結果相反。原因在於模型退化後出現了大量「推理循環」(Reasoning Loops),在單次回覆中反覆自我否定,不斷重來,用掉的 token 遠超節省的量。據 Stella Laurenzo 的數據,同期用戶主動中斷任務的比率飆升了 12 倍,開發者需要不停介入、糾錯、重新提交。
背後的邏輯是一個系統性錯誤。在複雜任務上減算力,並不會簡單地等比降低成本。一旦低於某個思考閾值,模型開始走彎路,總成本反而放大。調低 effort 在簡單查詢上省了錢,在程式工程任務上,它把帳單炸了。
「降智」這事,GPT-4 三年前演過一遍
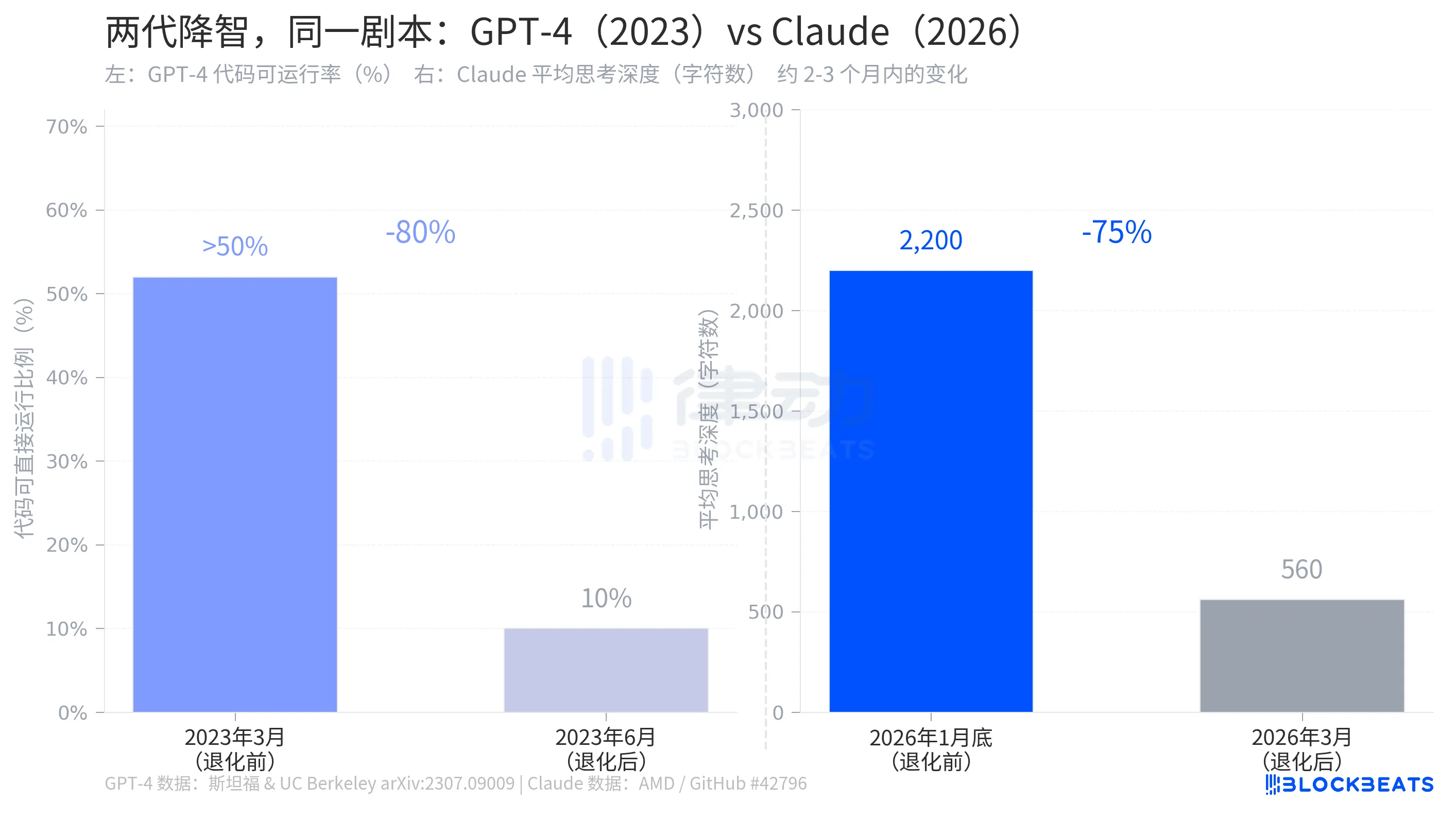
2023 年 7 月,斯坦福大學與加州大學伯克利分校的研究團隊在 arXiv 發表論文《How is ChatGPT's behavior changing over time?》,記錄了同一件事在 GPT-4 上的發生過程。
据該研究數據,2023 年 3 月的 GPT-4,生成的程式碼中超過 50% 可以直接運行。到 6 月,這個比例跌至 10%,跌幅約 80%,時間跨度三個月。同期,素數識別準確率從 97.6% 跌至 2.4%。OpenAI 的回應和 Anthropic 高度相似:後臺有過優化調整,屬於正常迭代。
兩個故事的結構幾乎一致,一家 AI 公司在後臺悄悄調整了影響模型能力的參數,用戶察覺到了,公司承認有過調整,但把原因解釋為「更合理的資源分配」。GPT-4 的退化發生在 2023 年,Claude 的退化發生在 2026 年,兩者相隔三年,劇本一樣。
這不是某家公司的特殊失誤。AI 訂閱模式的經濟邏輯決定了,當推理成本高於定價可以覆蓋的範圍時,廠商面臨的壓力是一樣的。調低默認思考強度,是目前成本和性能之間最容易拨動的那根旋鈕。用戶感知到的是模型「變笨了」。廠商帳面上節省的,是每次調用的邊際 token 成本。
Boris Cherny 給出了技術性解法,用戶可以通過 /effort high 指令或修改配置文件,手動把思考強度恢復至最高級別。這個解法在技術上可行,但它同時意味著,「最高性能」已經不再是默認設定。
345 美元到 42,121 美元,花掉的不只是預算,還有一個假設:廠商做的默認配置變更,是為了讓用戶的使用效果更好。
猜你喜歡

找到幾天幾十倍的「妖幣」,有秘笈嗎?

TAO 就是投了 OpenAI 的 Elon Musk,Subnet 就是 Sam Altman

公鏈上的「大規模代幣分發」時代已然落幕

飆升50倍,FDV超過100億美元,為什麼選擇RaveDAO?

10億枚DOT憑空鑄造,但黑客只賺了23萬美元
解析Noise新推出的Beta版本,如何在鏈上「炒熱度」?

龍蝦已成過去式?梳理那些讓你產能100x的Hermes Agent工具

向AI宣戰?火燒奧特曼住所背後的末日敘事

加密VC將死?市場淘汰周期已經開啟

邊緣地帶的回歸:一場圍繞海權、能源與美元的再博弈
Arthur Hayes 最新訪談:普通投資者如何應對伊朗戰爭?
剛剛,Sam Altman又被襲擊了,這次直接是開槍

加州州長簽署命令禁止預測市場內幕交易
加州州長Gavin Newsom頒布了一項行政命令,禁止州政府官員及其相關人員利用預測市場進行內幕交易。 該命令適用於“州長任命”的公職人員及其配偶、家庭成員和曾經的商業夥伴。 此措施旨在打擊內幕交易,避免以公職身份牟取不當利益。 美國國會也推出了類似法案,以進一步制止內幕交易行為。 南卡羅來納州等其他州份也開始關注並採用類似措施。 WEEX Crypto News, 預測市場內幕交易禁令概述 加州州長Gavin Newsom於2026年宣布了一項針對政府官員的嚴厲措施,旨在遏制他們利用內部信息牟取私利的行為。該命令明確禁止官員與他們的親屬使用工作中獲取到的任何非公開信息來參與預測市場,藉此從政治或經濟事件中獲利。這是一項旨在強化公職道德的重大舉措。 背景分析:內幕交易的風險與挑戰 內幕交易一直是金融市場的一大問題,而預測市場的興起更讓此問題變得複雜化。預測市場允許參與者就未來事件進行賭注,這種活動本身合法,但當公職人員利用職務便利獲取非公開信息賺取利益時,問題就變得敏感且嚴重。近期的幾起案例中,有人利用預測市場成功預測美國對伊朗的空襲,從中獲取巨額利益。這類事件引發了大眾和法律界的廣泛關注。 新法案與州政策的實施情況 在加州的帶動下,全美多州開始重新審視對預測市場的監管政策。美國國會議員Greg Casar和Chris Murphy提出的“BETS…

海峽封鎖,穩定幣補位|Rewire新聞早報
從高預期到爭議反轉,Genius空投「砍70%」引社區不滿
北京大興的小米汽車工廠,成了美國精英階層的新耶路撒冷

瘦Harness,胖Skill:100倍AI生產力的真正來源
