 Comprar cripto
Comprar cripto- Mercados
 Futuros
Futuros- Spot
- Copy trading
- Earn
- Más
El Viaje de Claude hacia la Insensatez en Diagramas: El Costo de la Austeridad, o Cómo la Factura de la API Aumentó 100 Veces
Hace unos días, Stella Laurenzo, Jefa de IA en AMD, publicó un problema titulado "Código de Claude Inutilizable para Tareas de Ingeniería Complejas" en el repositorio oficial de Claude Code. No se trataba de una queja emocional de un usuario, sino de un análisis cuantitativo basado en 6,800 sesiones. Puso de relieve el problema que la comunidad de IA más se resiste a enfrentar, con un conjunto de números que destacaba particularmente: un ajuste de configuración para ahorrar costos por parte de Anthropic disparó la factura mensual de la API de este equipo de $345 a $42,121.
El equipo de Laurenzo rastreó 235,000 invocaciones de herramientas, 18,000 indicaciones y documentó la degradación del rendimiento sistémico del Código de Claude desde febrero de 2026. Este informe fue posteriormente cubierto por The Register, desatando una tormenta de opinión pública de dos semanas en la comunidad de desarrolladores.
Boris Cherny, Jefe del equipo de Claude Code de Anthropic, proporcionó una explicación en Hacker News. El 9 de febrero, con el lanzamiento de Opus 4.6, se habilitó por defecto un mecanismo de "autopensamiento", donde el modelo decide de forma autónoma la duración del pensamiento. El 3 de marzo, Anthropic redujo el esfuerzo de pensamiento por defecto a 85. La explicación oficial fue "el punto de equilibrio óptimo entre inteligencia, latencia y costo." El impacto real de estos dos ajustes es evidente en los datos.
La Profundidad del Pensamiento Se Desploma en Tres Cuartas Partes
Según los datos del Problema de GitHub de Stella Laurenzo, la profundidad media del pensamiento de Claude Code experimentó un colapso en tres etapas durante dos meses: de un máximo de 2,200 caracteres a finales de enero a 720 caracteres a finales de febrero, una caída del 67%. Para marzo, se redujo aún más a 560 caracteres, una disminución del 75% desde el pico.
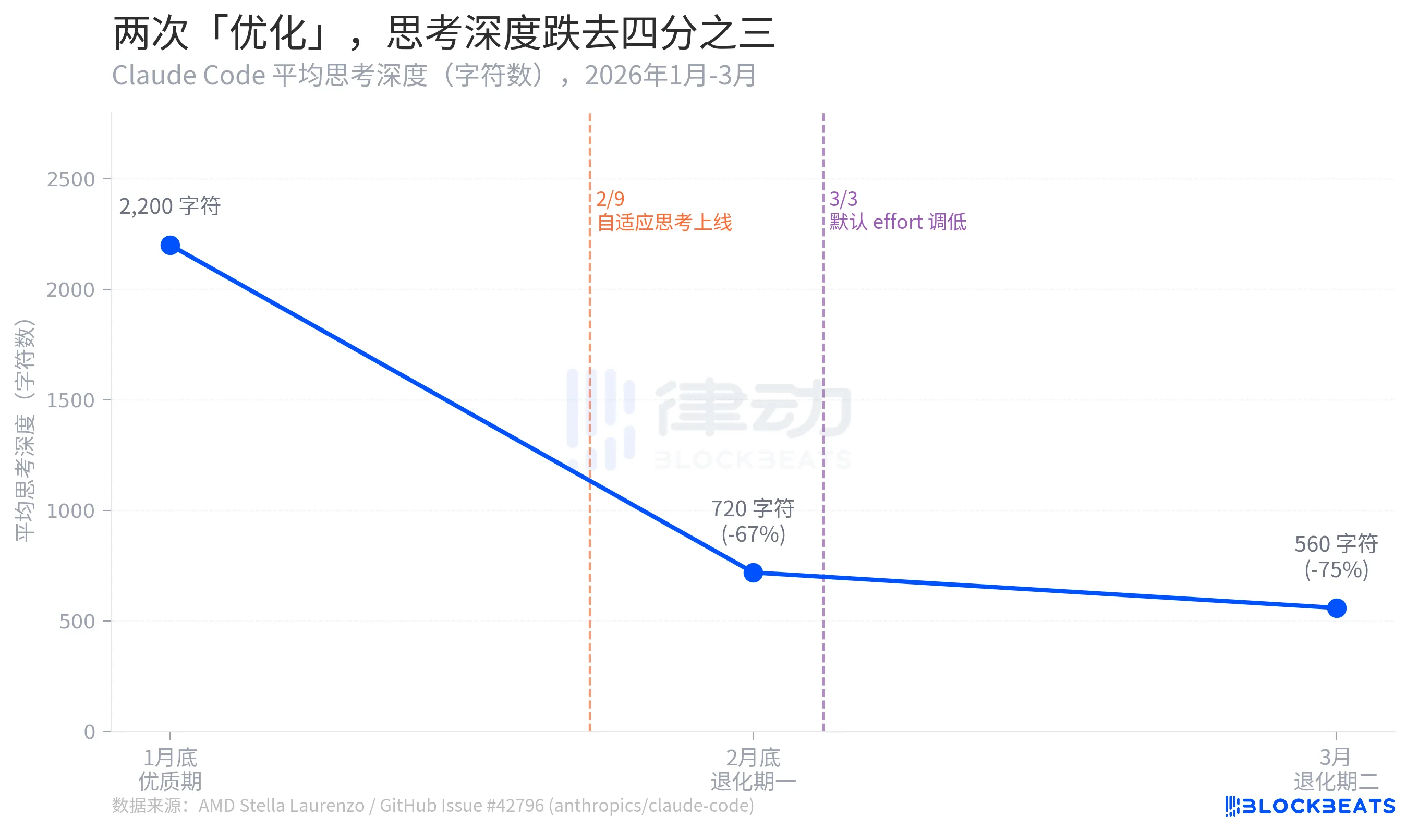
La profundidad del pensamiento aquí es una métrica proxy que refleja cuánto "deliberación interna" está dispuesto a involucrarse el modelo antes de proporcionar una respuesta. La diferencia entre 2,200 y 560 caracteres es aproximadamente equivalente a degradar de "redactar antes de responder" a "pensar durante dos segundos en tu cabeza antes de hablar."
Laurenzo también señaló que la función de "Redacción de Contenido del Pensamiento" (redact-thinking-2026-02-12) lanzada a principios de marzo, coincidió casualmente con el enmascaramiento del proceso de pensamiento del modelo durante este período, haciendo que la reducción fuera menos perceptible para los usuarios. Boris Cherny insiste en que esto fue meramente un cambio de interfaz y did-133">no afectó el razonamiento subyacente. Ambas afirmaciones son técnicamente válidas, pero desde la perspectiva del usuario, el efecto es indistinguible.
Boris Cherny más tarde reconoció que incluso al establecer manualmente el esfuerzo de nuevo al máximo, el mecanismo de auto-reflexión puede seguir asignando un razonamiento insuficiente en algunas rondas, lo que lleva a contenido alucinado. "Restaurar el esfuerzo máximo" no es una solución completa; simplemente acerca la perilla a su posición original en lugar de restaurarla a su determinismo original.
De "Programador Orientado a la Investigación" a "Programador de Edición Ciega"
Un detalle en el informe de Stella Laurenzo es más explícito que la profundidad de pensamiento: cuántos archivos relevantes el modelo lee activamente antes de realizar cambios en el código.
Según los datos de GitHub Issue, durante el período principal, la relación promedio de lectura a edición es de 6.6. Antes de realizar un cambio en el código, el modelo, en promedio, lee 6.6 archivos para entender el contexto. Durante el período de decadencia, este número cae a 2.0, una disminución del 70%. Más críticamente, aproximadamente un tercio de las ediciones de código ocurren sin que el modelo lea el archivo objetivo, lanzándose directamente.
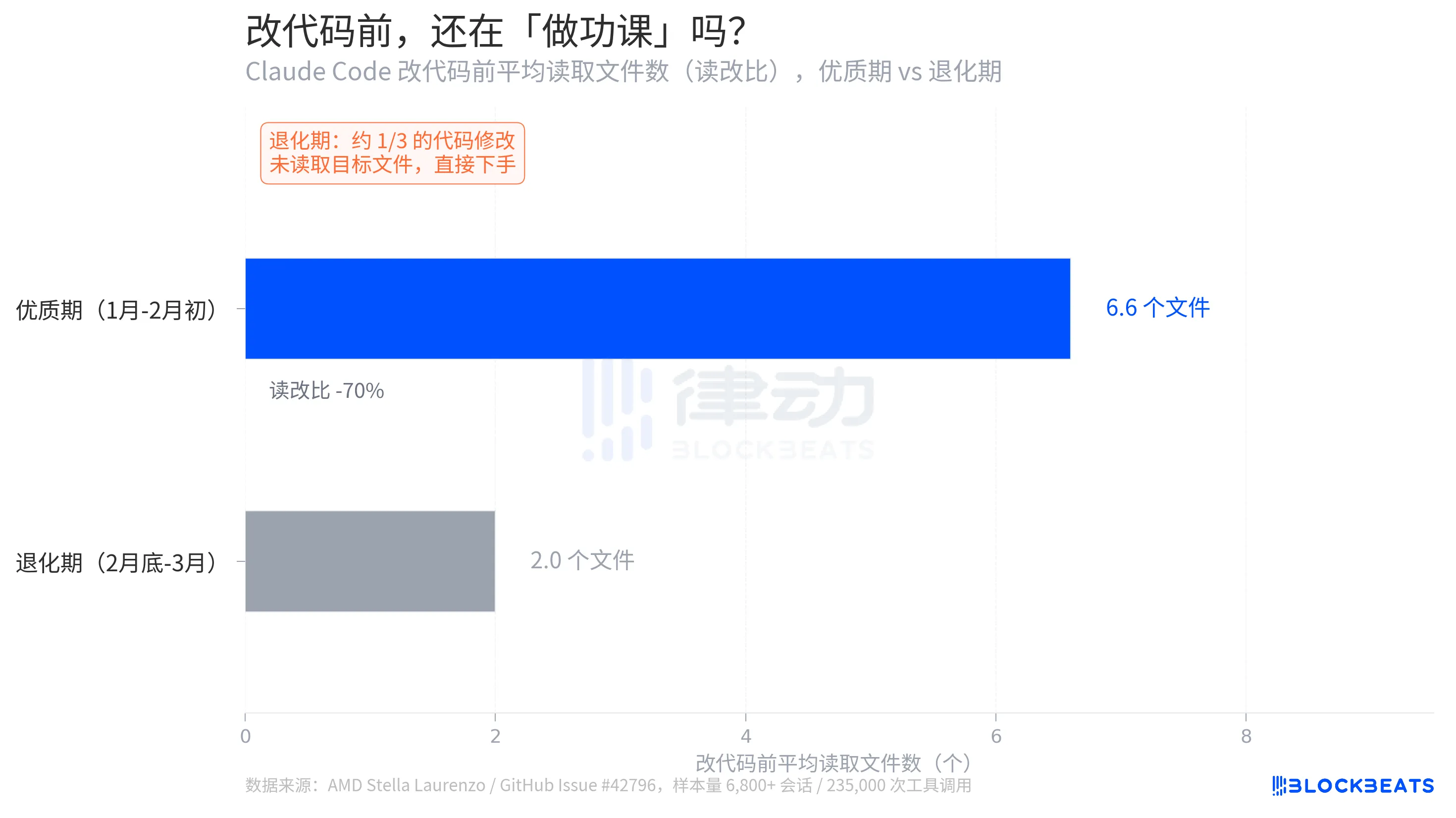
Laurenzo se refiere a esto como "ediciones ciegas." En términos de ingeniería, esto es similar a un programador escribiendo código sin mirar las firmas de función o conocer los tipos de variables. "Cada ingeniero senior en mi equipo ha tenido experiencias similares de primera mano," escribió en su informe. "Claude ya no puede ser confiado para llevar a cabo tareas de ingeniería complejas."
La caída de una relación de lectura a edición de 6.6 a 2.0 no es meramente un cambio en la métrica de comportamiento; significa un colapso en las tasas de éxito de tareas de. La complejidad de los repositorios de código modernos dicta que cualquier modificación involucra dependencias a través de múltiples archivos. Saltar la exploración del contexto y hacer cambios directamente no conduce meramente a "respuestas incorrectas" sino más bien a "cambios aparentemente correctos que desencadenan nuevos errores más adelante." El costo de depurar tales errores supera con creces el de una única respuesta explícita fallida.
La Paradoja de "Ahorrar Dinero"
Uno de los conjuntos de números más contraintuitivos en todo el incidente proviene de los mismos datos de GitHub Issue: El equipo de Stella Laurenzo vio cómo los costos mensuales de invocación de la API de Claude Code se desplomaron de 345 dólares en febrero de 2026 a la asombrosa cifra de 42,121 dólares en marzo, un aumento de 122 veces.
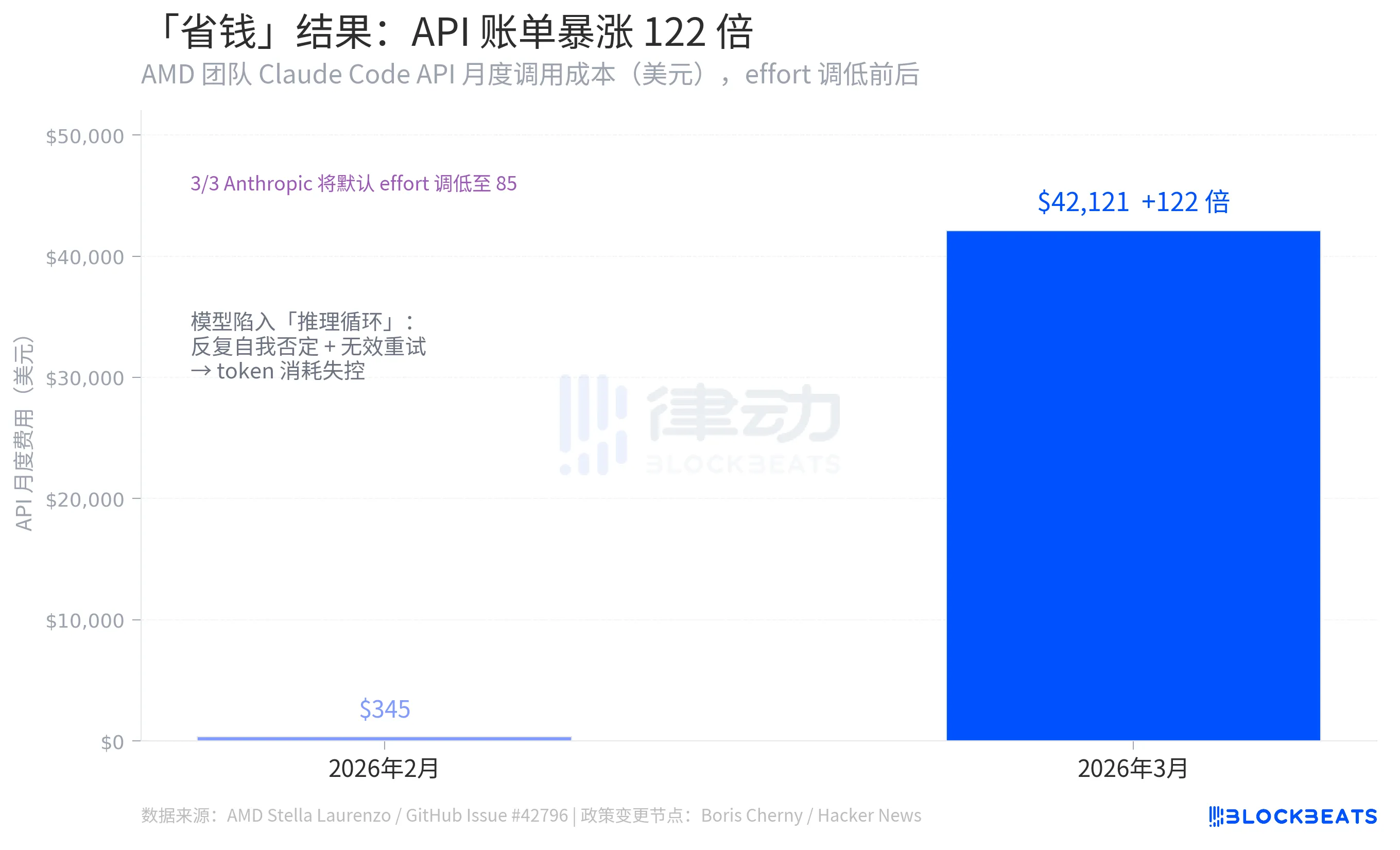
La lógica detrás de la reducción de esfuerzo de Anthropics era disminuir el consumo de tokens por llamada, reduciendo así los costos. Sin embargo, el resultado fue el opuesto. La razón detrás de esto fue la aparición de numerosos "bucles de razonamiento" tras la degradación del modelo, lo que llevó a una auto-negación repetida dentro de una única respuesta, reinicios constantes y un consumo de tokens que superaba con creces la cantidad ahorrada. Según los datos de Stella Laurenzo, la tasa de usuarios que abortaban tareas voluntariamente aumentó 12 veces durante el mismo período, requiriendo la intervención continua de los desarrolladores, correcciones y reenvíos.
La lógica subyacente es un error sistémico. Reducir la potencia computacional en una tarea compleja no simplemente reduce proporcionalmente los costos. Una vez que se está por debajo de un cierto umbral de pensamiento, el modelo comienza a desviarse, y el costo total acaba escalando. Reducir el esfuerzo ahorró dinero en consultas simples, pero en tareas de codificación, disparó la factura.
La cuestión de "Dumbing Down", GPT-4 lo hizo hace tres años.
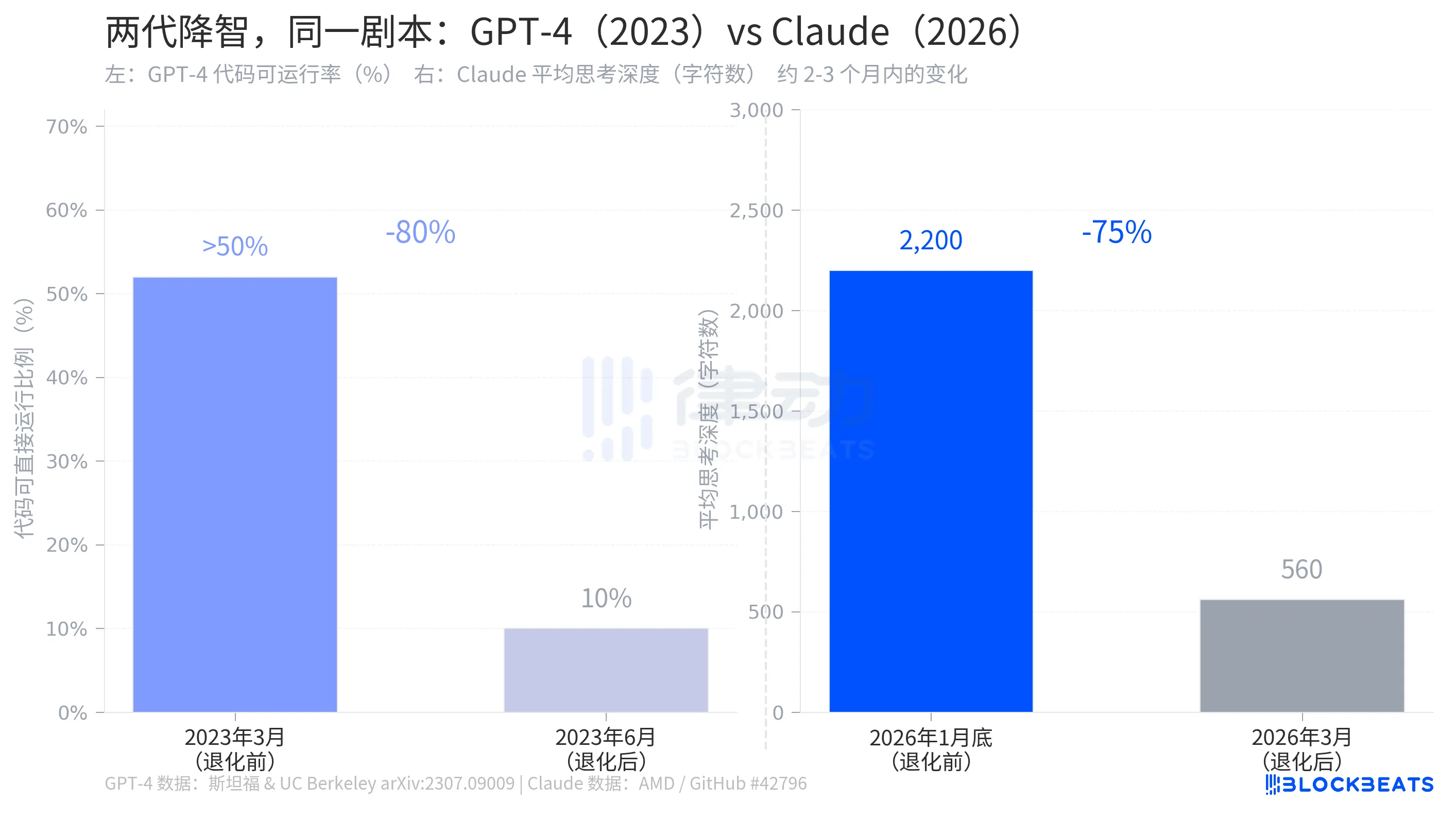
En julio de 2023, un equipo de investigación de la Universidad de Stanford y la Universidad de California, Berkeley, publicó un artículo en arXiv titulado "¿Cómo está cambiando el comportamiento de ChatGPT con el tiempo?", documentando el mismo fenómeno que ocurre en GPT-4.
Según los datos de la investigación, en marzo de 2023, GPT-4 había generado código donde más del 50% era directamente ejecutable. Para junio, esta proporción había caído al 10%, una disminución del 80% en tres meses. Durante el mismo período, la precisión en la identificación de números primos se desplomó del 97.6% al 2.4%. La respuesta de OpenAI fue muy similar a la de Anthropic: había habido optimizaciones en segundo plano, parte de la iteración normal.
La estructura de las dos historias es casi idéntica: una empresa de IA ajustó silenciosamente parámetros que afectan las capacidades del modelo en segundo plano, los usuarios lo notaron, la empresa reconoció el ajuste, pero lo explicó como "una asignación de recursos más razonable." La degradación de GPT-4 ocurrió en 2023, la degradación de Claude sucedió en 2026, tres años de diferencia, pero el guion es el mismo.
Esto no es un error peculiar de una empresa específica. La lógica económica de los modelos de suscripción de IA determina que cuando los costos de razonamiento superan el precio que se puede cubrir, los fabricantes enfrentan la misma presión. Reducir la intensidad de pensamiento por defecto es actualmente la perilla más fácil de ajustar entre costo y rendimiento. Lo que los usuarios perciben es que el modelo se está volviendo "más tonto." Lo que el fabricante ahorra en los libros es el coste marginal por llamada.
Boris Cherny ha proporcionado una solución técnica donde los usuarios pueden restaurar manualmente la intensidad del pensamiento al nivel más alto a través del comando /esfuerzo alto o modificando el archivo de configuración. Esta solución es técnicamente viable, pero también significa que "máximo rendimiento" ya no es la configuración predeterminada.
De 345 a 42,121 dólares, lo que se gastó no fue solo el presupuesto, sino también una suposición: los cambios en la configuración predeterminada realizados por el fabricante estaban destinados a mejorar la experiencia del usuario.
Te puede gustar

He encontrado una "meme coin" que se disparó en solo unos días. ¿Algún consejo?

TAO es Elon Musk, quien invirtió en OpenAI, y Subnet es Sam Altman

La era de la "distribución masiva de monedas" en cadenas públicas llega a su fin.

Con un aumento de 50 veces, con un FDV superior a 10.000 millones de USD, ¿por qué RaveDAO?
La versión beta recién lanzada de Parse Noise, ¿cómo "enlazar" este calor?

Se acuñaron 1.000 millones de DOTs de la nada, pero el hacker solo ganó 230.000 dólares

¿Cuándo terminará la guerra tras el bloqueo del Estrecho de Ormuz?

Antes de usar X Chat, el «WeChat occidental» de Musk, debes tener claras estas tres cuestiones
La aplicación X Chat estará disponible para su descarga en la App Store este viernes. Los medios de comunicación ya han informado sobre la lista de funciones, que incluye mensajes que se autodestruyen, la prevención de capturas de pantalla, chats grupales de hasta 481 personas, la integración con Grok y el registro sin necesidad de un número de teléfono, y la han calificado como el «WeChat occidental». Sin embargo, hay tres cuestiones que apenas se han abordado en ningún informe.
Hay una frase en la página de ayuda oficial de X que sigue ahí: «Si personas malintencionadas dentro de la empresa o la propia X provocan que las conversaciones cifradas queden al descubierto a raíz de procedimientos legales, ni el remitente ni el destinatario se darán cuenta en absoluto».
No. La diferencia radica en dónde se almacenan las claves.
En el cifrado de extremo a extremo de Signal, las claves nunca salen de tu dispositivo. Ni X, ni el tribunal, ni ninguna tercera parte tiene tus claves. Los servidores de Signal no disponen de nada que permita descifrar tus mensajes; incluso si se les exigiera mediante una citación judicial, solo podrían facilitar las marcas de tiempo de registro y las horas de la última conexión, tal y como demuestran los registros de citaciones judiciales anteriores.
X Chat utiliza el protocolo Juicebox. Esta solución divide la clave en tres partes, cada una de las cuales se almacena en uno de los tres servidores gestionados por X. Al recuperar la clave con un código PIN, el sistema recupera estos tres fragmentos de los servidores de X y los vuelve a combinar. Por muy complejo que sea el código PIN, X es quien realmente custodia la clave, no el usuario.
Este es el trasfondo técnico de la «frase de la página de ayuda»: dado que la clave se encuentra en los servidores de X, X tiene la capacidad de responder a procedimientos legales sin que el usuario lo sepa. Signal no tiene esta capacidad, no por una cuestión de política, sino porque simplemente no dispone de la clave.
La siguiente ilustración compara los mecanismos de seguridad de Signal, WhatsApp, Telegram y X Chat en seis aspectos. X Chat es la única de las cuatro en la que la plataforma conserva la clave y la única que carece de confidencialidad hacia adelante.
La importancia de la confidencialidad hacia adelante radica en que, aunque una clave se vea comprometida en un momento dado, los mensajes anteriores no pueden descifrarse, ya que cada mensaje cuenta con una clave única. El protocolo Double Ratchet de Signal actualiza automáticamente la clave después de cada mensaje, un mecanismo del que carece X Chat.
Tras analizar la arquitectura de XChat en junio de 2025, Matthew Green, profesor de criptología de la Universidad Johns Hopkins, comentó: «Si consideramos XChat como un sistema de cifrado de extremo a extremo, esta vulnerabilidad parece ser de las que suponen el fin del juego». Más tarde añadió: «No confiaría en esto más de lo que confío en los mensajes directos actuales sin cifrar».
Desde el informe de TechCrunch de septiembre de 2025 hasta su puesta en marcha en abril de 2026, esta arquitectura no sufrió ningún cambio.
En un tuit publicado el 9 de febrero de 2026, Musk se comprometió a someter X Chat a rigurosas pruebas de seguridad antes de su lanzamiento en X Chat y a publicar todo el código en código abierto.
A fecha del 17 de abril, fecha de lanzamiento, no se ha realizado ninguna auditoría independiente por parte de terceros, no existe un repositorio oficial del código en GitHub y la etiqueta de privacidad de la App Store revela que X Chat recopila cinco o más categorías de datos, entre los que se incluyen la ubicación, la información de contacto y el historial de búsqueda, lo que contradice directamente la afirmación publicitaria de «Sin anuncios, sin rastreadores».
No se trata de una supervisión continua, sino de un punto de acceso claro.
En cada mensaje de X Chat, los usuarios pueden mantener pulsado y seleccionar «Preguntar a Grok». Al hacer clic en este botón, el mensaje se envía a Grok en texto sin cifrar, pasando de estar cifrado a estar sin cifrar en esta fase.
Este diseño no es una vulnerabilidad, sino una característica. Sin embargo, la política de privacidad de X Chat no especifica si estos datos en texto sin cifrar se utilizarán para el entrenamiento del modelo de Grok ni si Grok almacenará el contenido de estas conversaciones. Al hacer clic en «Pregúntale a Grok», los usuarios desactivan voluntariamente la protección de cifrado de ese mensaje.
También hay un problema estructural: ¿Cuánto tardará este botón en pasar de ser una «función opcional» a convertirse en un «hábito habitual»? Cuanto mayor sea la calidad de las respuestas de Grok, más a menudo recurrirán a él los usuarios, lo que provocará un aumento en la proporción de mensajes que quedan fuera de la protección del cifrado. La solidez real del cifrado de X Chat, a la larga, depende no solo del diseño del protocolo Juicebox, sino también de la frecuencia con la que los usuarios hagan clic en «Ask Grok».
La versión inicial de X Chat solo es compatible con iOS; en cuanto a la versión para Android, solo se indica «próximamente», sin especificar una fecha concreta.
En el mercado mundial de teléfonos inteligentes, Android cuenta con una cuota de mercado de aproximadamente el 73 %, mientras que iOS tiene alrededor del 27 % (IDC/Statista, 2025). De los 3.140 millones de usuarios activos mensuales de WhatsApp, el 73 % utiliza Android (según Demand Sage). En la India, WhatsApp cuenta con 854 millones de usuarios, con una penetración de Android superior al 95 %. En Brasil hay 148 millones de usuarios, de los cuales el 81 % utiliza Android, y en Indonesia hay 112 millones de usuarios, de los cuales el 87 % utiliza Android.
El dominio de WhatsApp en el mercado mundial de las comunicaciones se basa en Android. Signal, con una base de usuarios activos mensuales de unos 85 millones, también cuenta principalmente con usuarios preocupados por la privacidad en países donde predomina Android.
X Chat eludió este campo de batalla, lo que da lugar a dos posibles interpretaciones. Una de ellas es la deuda técnica; X Chat está desarrollado en Rust, y lograr la compatibilidad multiplataforma no es fácil, por lo que dar prioridad a iOS puede suponer una limitación desde el punto de vista técnico. La otra es una decisión estratégica; dado que iOS cuenta con una cuota de mercado de casi el 55 % en Estados Unidos y que la base de usuarios principal de X se encuentra en ese país, dar prioridad a iOS significa centrarse en su base de usuarios principal, en lugar de entrar en competencia directa con los mercados emergentes, dominados por Android, y con WhatsApp.
Estas dos interpretaciones no son mutuamente excluyentes y conducen al mismo resultado: Con su lanzamiento, X Chat renunció voluntariamente al 73 % de los usuarios de teléfonos inteligentes de todo el mundo.
Algunos han descrito este asunto de la siguiente manera: X Chat, junto con X Money y Grok, forma un trío que crea un sistema de datos de circuito cerrado paralelo a la infraestructura existente, similar en su concepto al ecosistema de WeChat. Esta valoración no es nueva, pero con el lanzamiento de X Chat, merece la pena volver a examinar el esquema.
X Chat genera metadatos de comunicación, incluida información sobre quién habla con quién, durante cuánto tiempo y con qué frecuencia. Estos datos se introducen en el sistema de identidad de X. Parte del contenido del mensaje pasa por la función «Ask Grok» y entra en la cadena de procesamiento de Grok. Las transacciones financieras las gestiona X Money: las pruebas públicas externas concluyeron en marzo y el servicio se abrió al público en abril, lo que permite realizar transferencias entre particulares de dinero fiduciario a través de Visa Direct. Un alto cargo de Fireblocks ha confirmado los planes para poner en marcha los pagos con criptomonedas a finales de año, ya que actualmente la empresa cuenta con licencias de transferencia de fondos en más de 40 estados de EE. UU.
Todas las funciones de WeChat se ajustan al marco normativo de China. El sistema de Musk opera dentro de los marcos normativos occidentales, pero él también ocupa el cargo de director del Departamento de Eficiencia Gubernamental (DOGE). No se trata de una réplica de WeChat, sino de una recreación de la misma lógica en un contexto político diferente.
La diferencia es que WeChat nunca ha afirmado explícitamente en su interfaz principal que cuente con «cifrado de extremo a extremo», mientras que X Chat sí lo hace. En la percepción de los usuarios, el «cifrado de extremo a extremo» significa que nadie, ni siquiera la plataforma, puede ver tus mensajes. El diseño arquitectónico de X Chat no cumple con esta expectativa de los usuarios, pero utiliza este término.
X Chat concentra en manos de una sola empresa la información relativa a «quién es esta persona, con quién habla y de dónde procede y a dónde va su dinero».
La frase de la página de ayuda nunca ha sido solo una serie de instrucciones técnicas.

¿La langosta es cosa del pasado? Desempaquetando las herramientas del agente Hermes que multiplican su rendimiento por 100.

¿Declarar la guerra a la IA? La narrativa apocalíptica detrás de la residencia en llamas de Ultraman
¿Los VC de criptomonedas están muertos? El ciclo de extinción del mercado ha comenzado

Regresión de terrenos en los bordes: Un repaso al poder marítimo, la energía y el dólar.
Última entrevista con Arthur Hayes: ¿Cómo deberían los inversores minoristas afrontar el conflicto con Irán?
Hace un momento, Sam Altman fue atacado de nuevo, esta vez a tiros.

Resumen del bloqueo del estrecho y las stablecoins | Edición matutina de Rewire News

El gobernador de California firma una orden para prohibir el uso de información privilegiada en los mercados de predicción
Gavin Newsom, el gobernador de California, ha firmado una orden ejecutiva que busca restringir el uso de información…
De grandes expectativas a un giro polémico: el airdrop de Genius provoca una fuerte reacción en la comunidad.